

自12月18日阿里云香港可用区C因为机房水冷机组出现故障,导致一次阿里云历史上最长的宕机后,官方终于在圣诞节那天,出具了一份非常翔实的调查报告《关于阿里云香港Region可用区C服务中断事件的说明》,称得上是实事求是面对问题了。
我从业十五年,参与建设过4000个节点的私有云,也搞过机房装修和上架,还有一点运维经验,算是有相关经验,跟大家讨论一下以后自家单位的容灾应该怎么做吧。
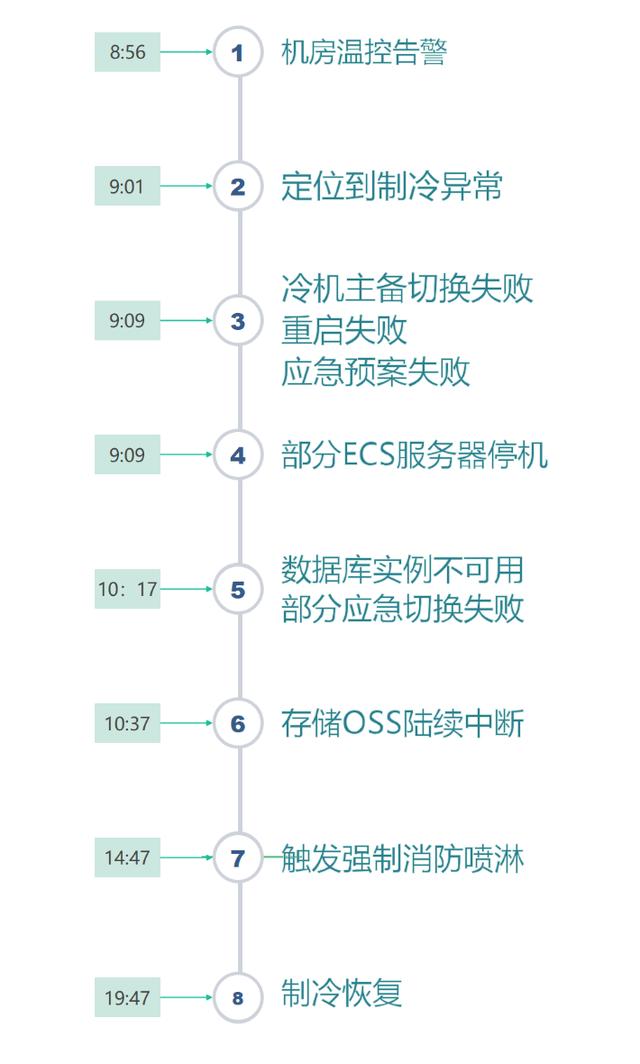
大家先看这次阿里云宕机事故的重点时间线,8点56就发现机房温控告警了,然后9点01就正确定位到制冷异常了。这个问题阿里云没有隐瞒的必要,因为机房突然升温,只能是空调(冷机)故障了。
这个事故的主要原因,就是因为制冷设备整整10个小时不能恢复工作,机房升温太快,工程师为了保护数据,只能逐步关机。

次要原因是,在关机后还是有某个包间因为温度过高导致喷淋装置启动。手机和电脑不能进水都已经是常识了,服务器上淋了水那还得了?

再次原因,就是阿里云香港Reigon的架构设计,同样没有遵循自己提到的「全链路多可用区的业务架构设计」,新扩容的ECS管控系统启动时依赖的中间件服务部署在可用区C机房,导致可用区C一旦宕机,扩容服务也启动不了。相信后续阿里云一定会全网巡检,整体优化多可用区高可用设计,避免制造单点故障,类似依赖OSS单AZ和中间件单AZ的问题,再次出现就说不过去了。


第四个原因,是对于云服务来说,高可用架构能够保障是某几台物理服务器(ECS、OSS、RDS)因为故障宕机时,原来的应用可以漂移到同一个AZ(可用区)的其他服务器上,保证服务的连续性和数据的可用性。但是原有复杂的分布式架构在一个AZ(可用区)整体出现网络、服务器、存储全部下线的时候,国内没有厂家敢于承诺100%实现全量无伤漂移到其他可用区,或者其他机房的。
打个比方,如果把中国大陆看成一个CN可用区,那么当武汉或者上海出现疫情的时候,是能够把病人疏散到其他城市去治疗,缓解自身医疗压力的。但是当举国上下都遭遇新冠的时候,病人还能往哪送?阿里云这次遭遇的是一个AZ(可用区)整体下线,里面近千个机柜、上万台设备的数据,又能切换到哪里?
第五个原因,是对极小概率事件的应急预案,是没法考虑得那么周详的,甚至完全考虑不到。比如谁能提前考虑服务器被喷淋装置喷水导致损坏的场景?谁能考虑一个主备配置4+4的水冷机组,能够同时出现故障,修好却需要10个小时?
第六个原因,是对于一个巨型系统来说,有能力搞清楚里面所有的细节的总工程师,一定在新项目上,绝不是去搞运维浪费人才。其他的成员都是分模块承担任务的,他们只能选择信任其他模块。例如搞数据库(RDS)的同学关注的是支持跨区迁移,谁能考虑到跨区迁移依赖的反向代理竟然不是跨区高可用的,结果大部分数据库成功迁移了,但是香港可用区C一旦宕机,依赖这个反向代理的的数据库就迁移不了。

所以,我来点评一下。
1、假的主备冷机系统
阿里云宕机的主要原因是机房主备水冷机组共用了同一个水路循环系统,存在单点故障,修这个就用了10个小时。然而这个机房还只是阿里云租的。查了一下阿里云香港C区所在的机房,应该是下图的香港粉岭安汇中心/安乐电话机房。(来自知乎@香港sim精神小伙)

这个机房原来是PCCW电讯盈科的,然后Vantage(数据中心园区提供商,其母公司是纽交所上市公司,代码DBRG)在2021年刚刚收购了电讯盈科的数据中心。
《Vantage Data Centers 完成对 PCCW DC 的收购,将其一流的超大规模数据中心平台带到香港和吉隆坡 – Vantage Data Centers》
这两栋机房同属Vantage的HKG1园区,大概机房参数如下:
所以阿里云也是倒霉,租了个机房还换了东家。换了东家之后,最了解情况的中基层领导很可能已经被扫地出门了,Twitter不就是这样么?所以故障响应就会不及时。
修个水冷机组还要用10个小时,其中真正有效的时间就是排水补气的3小时,除此之外,定位原因怎么要用3个半小时的?这个水冷机组的服务商也挺废物的。
定位原因的3个半小时,就是设备维护商赶到现场的时间。一个重要数据中心的冷机坏了,香港的设备维护上用了3个半小时才到达现场,这种服务水平和响应速度极不可靠,从深圳到广州也用不了三个小时吧。
另外,解锁群控逻辑,手动启动4台冷机,竟然要用3小时32分,也说明服务商的工程师对这个系统根本都不熟,大概率是照着操作手册现学现卖的。

2020年,微软Azure位于美国东部的数据中心发生服务中断,持续六小时。微软披露说,冷却系统故障是导致这次停机的原因,发生故障的楼宇自动化控制导致气流减少,随后整个数据中心的温度峰值阻碍了网络设备的性能,使计算和存储实例无法访问。但是微软的信息披露没有阿里云这一次这么翔实,这一点还是要给阿里云的实事求是点个赞。
2021年11月,网易游戏机房大规模服务器宕机,原因同事是机房过热,空调重新开机也没有解决问题。但幸好这只是游戏服务器,玩家是可以接受的。但是大陆的服务更到位,网易的宕机只用了3小时就恢复了。
2022年夏天,伦敦的谷歌云及甲骨文数据中心出现制冷系统故障,导致数据中心气温升高,产生宕机。甲骨文的是系统自动采取保护措施关闭作业,于是业务宕机;谷歌的是温度过高导致存储故障,引起虚拟机宕机,然后谷歌也关闭了一部分机器。
2、数据中心机房用喷淋
所以根据《建筑设计防火规范》GB50016规定,重要机房、配电房是需要做气体自动灭火,这是中国大陆的规定。
但是我国的国标之间也有冲突,比如根据《《数据中心设计规范》GB 50174-2017》,只要数据中心的系统在其他数据中心内有承担相同功能的备份系统时,也可以设置自动喷水灭火系统。这个规范的主编单位是中国电子工程设计院。

我在2010年参与了苏州国科数据中心Tier-IV机房项目,当时是东北亚最高端的机房,那时候我们用的就是七氟丙烷气体灭火。参见《运营环境 苏州国科数据中心》

为什么要用对人体有微毒性的七氟丙烷灭火,而不是用干粉、气水雾或者喷淋方式灭火呢?因为电子设备就没有不怕水的,干粉也会对设备造成伤害。顺口再说一句,国外声称他们重视员工生命,所以建议少用这种有毒的气体灭火方式。这方面很多公司都参考了美国消防协会NFPA的标准,国际某个头部的云厂商也有不少这类设计。
我参与的项目还是经受住了考验,2022年10月13日,苏州国科数据中心A2栋建筑屋顶备用冷却塔起火,半小时后扑灭,但是建筑内的苏州超算中心数据机房安然无恙,数据没受影响,说明气体灭火还是极有必要的,要不然超算中心就无了。

当然,气体灭火也有弊端,比如对空间有要求,大于3600平方就达不到消防效果,这些在国标里都有提及。此外气体的储备量也是有限制的。
这个机房原来是PCCW电讯盈科的,也是资深数据中心运营商,真的会这么离谱么?《电讯盈科PowerBase方案》里面也写的非常清楚,数据中心对制冷机组、供电机组全年无休监控。现在看来,制冷机组的监控明显失灵,反而是机房先升温告警,然后才找到了制冷机组的问题。

虽然这次故障的源起是机房。但硬件设备的能力和可靠性是有限的,这就是为什么有云计算的原因。我认为,我们需要提升数据中心设施的可靠性,但不应该只专注于此。云计算不应当如此严重的依赖于单个机房,阿里云更应该做的是提升云产品的稳定性,加强整个AZ层面的灾备演练。
我们该怎么自保?
IDC圈盘点了近几年的前十大数据中心灾难事故,《盘点:近年数据中心十大灾难事件_机房_火灾_服务器》,包括2020年韩国SK公司数据中心火灾,影响了3.2万个服务器;2021年3月,欧洲云计算巨头OVH在法国的数据中心严重火灾,一共4座数据中心,有一座被完全烧毁。导致法国360个政府、企业与公共事业网站直接瘫痪。

2021年,河南多机房因汛情断电,还有位于河南的数据中心出现机房进水情况;2022年谷歌数据中心电气爆炸,影响了40多个国家的1338台服务器。这种事一篇稿子都写不下。

所以,重要应用和数据,请务必做到狡兔三窟,一定要充分考虑云主机的单点故障,做好多可用区的高可用,做好数据的容灾和备份;千万不要全盘相信连锁型的自动化操作。
在极端情况下,全自动化操作容易导致出现多米诺骨牌一样的连锁反应。比如这次阿里云香港机房的冷机就是群控启动的,死活就启动不起来。因为再完备、再安全、再可靠的自动化方案,哪怕平时运转非常正常,赶上寸劲和巧合,总会出现无法预计的问题。
人体的设计也有这种Bug,当免疫系统在体内杀新冠病毒杀疯了的时候,他才不会管人体是否受得了,直接烧到42度,或者免疫风暴走起。反正新冠病毒总得死,但是人会不会死,免疫系统不在乎。
自动喷淋灭火系统也是,反正只要温度过高我就要喷水,我的任务是保证火被扑灭了,但是物理服务器进水会不会损坏,自动喷淋灭火系统不在乎。特斯拉也是,他的自动控制系统只负责接管车辆驾驶,至于是不是刹车失败,会不会造成人员伤亡,自动控制系统不在乎。
我的群晖NAS有100T的容量,其中有5T工作文档数据,算是我十五年来攒下的命根子。两个月之前,我在三天里连续坏了两块硬盘,真的是吓出一身冷汗;我做了Raid5,如果只坏一块盘,数据是可以恢复的;但是如果同时坏了两块盘,那我事务的数据就全game over了。

在这件事情之后,我直接搞了个同城灾备和异地容灾。同城灾备是我买了一块16T的硬盘,接在群晖NAS上,把我的重要数据每日备份;异地容灾就是一年几百块买了阿里云盘,映射成WebDAV,也是每天备份我的重要数据,这样才能保证数据可靠性。
对于应用服务来说,一定要考虑好安全性,比如反亲和性,两台虚拟机不要放在同一台物理机上;比如做好镜像备份和容器的编排,在异地设置好备份,保证必要的时候可以快速在异地拉起容器;比如做好数据库的异步同步,基本保证数据的一致性,在应用里不要直接写死数据库的IP地址,还是要用域名指向。
比如2019年3月,腾讯云上海南汇机房的光缆被施工挖断,等于所有网络都不通了,暖暖、QQ 飞车,王者荣耀,吃鸡等 90 多个服务受到影响,这种问题就属于意外,也没法问责云厂商。
所以,如果老板问为什么要花这么多资金和人力来搞容灾,那就可以告诉老板,不管是谷歌云、甲骨文、微软云、阿里云、还是腾讯云,全都出过故障,只要是服务,就有不可用的时候,所以靠谁不如靠自己。像阿里云这次故障中,在架构层面设计了多可用区高可用方案的客户,就完全没有受到影响,当然,安全是需要额外成本的。
每个公司都是自己业务应用和数据的第一责任人,不应该也不能把希望全部寄托在云厂商身上。
比如2021年3月,云厂商OVH在法国的数据中心起火之后,游戏《Rust》表示,25台欧洲服务器完全损毁,没有备份,数据无法被修复。你说这个数据丢失的主责是云厂商OVH,还是游戏运营商呢?像阿里云香港机房本月的可用时间大约是98%左右,也会按照规则赔偿25%的月费用,但是用户的业务稳定和数据安全,能全部依赖于供应商么?当然不能。
阿里云这一次的信息披露,算是这么多家云厂商中最坦诚、最详尽的了,也是给各个企业一个充分的经验借鉴,让大家在容灾方案设计时,除了保证应用和数据的高可用,还要考虑中间件的高可用;除了考虑自身的架构设计,也要考虑租赁的数据中心的制冷和防火设计者有没有脑血栓
毕竟人生中充满了黑天鹅事件,我们除了积极应对风险,还能怎么办呢?狡兔务必三窟就是唯一的答案。
参考资料
[1]
香港sim精神小伙: https://www.zhihu.com/people/15217944045
[2]
Vantage Data Centers 完成对 PCCW DC 的收购,将其一流的超大规模数据中心平台带到香港和吉隆坡 – Vantage Data Centers: https://vantage-dc.com/news/vantage-data-centers-finalizes-pccw-dc-acquisition-to-bring-its-best-in-class-hyperscale-data-center-platform-to-hong-kong-and-kuala-lumpur/
[3]
运营环境 苏州国科数据中心: http://m.sisdc.com.cn/operatingEnvi.html
[4]
电讯盈科PowerBase方案: https://www.pccwsolutions.com/getitem.php?id=652543d8-a258-4127-bee4-483bf69054c5
[5]
盘点:近年数据中心十大灾难事件_机房_火灾_服务器: https://www.sohu.com/a/609305338_210640


评论前必须登录!
注册